M01·RAG and Context Engineering
FinVault - RAG for Financial Documents
Build a full-stack RAG application with FastAPI backend, Streamlit frontend, and Server-Sent Events for real-time streaming. The complete financial document analyst.
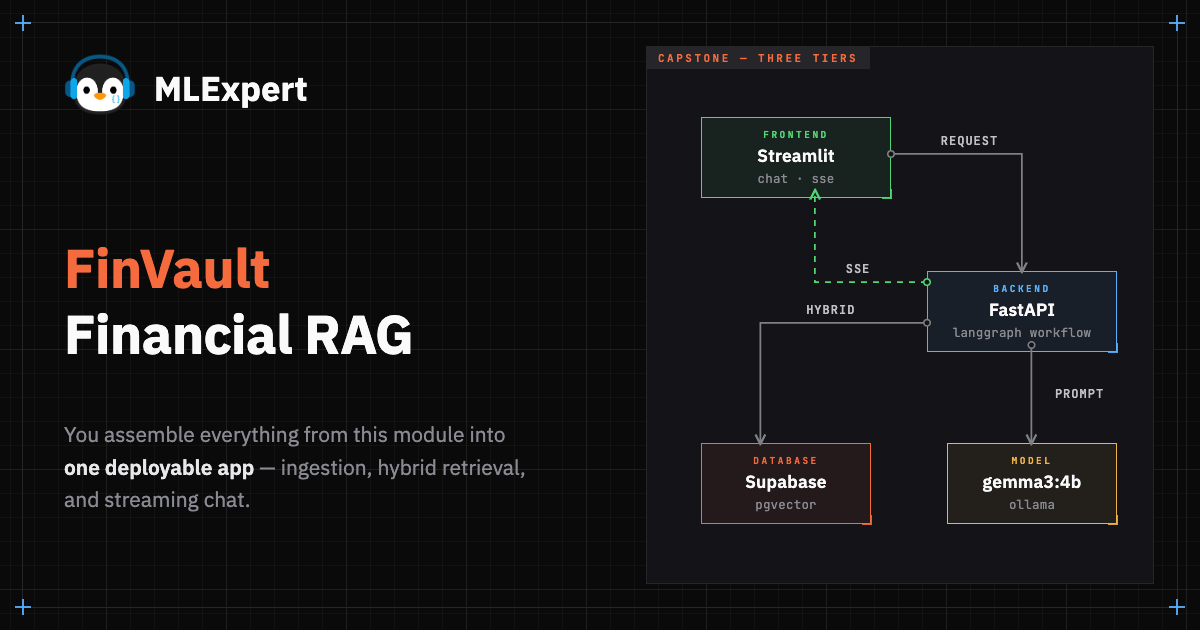
This capstone project is harder, but it's also more rewarding. You're ready to accomplish this!
You'll build a complete RAG system that can answer questions about financial documents. It will work completely offline (private) and allow you to analyze publicly available financial documents. At the end, you'll have a full-stack application you can deploy anywhere.
Project Specification
Members onlyJoin 900+ members
Members only from here
This lesson is part of the full AI engineering roadmap. Here's what unlocking gives you.
What you unlock
- 01All 6 modules · 40+ hands-on tutorials
- 02Source code, repositories, and architecture diagrams
- 03Portfolio artifacts: apps, APIs, eval reports, dashboards, capstones
- 04Live sessions + every recording
- 05Discord community access
- 06Certificate of completion with public verification URL
Price·lifetime
$299$197·Pay once
price goes up August 1
30-day money-back guarantee. One email, full refund.
or
“Best educational investment in my ML/AI journey.”
Ana Clara Medeiros·AI Developer
Instant access after paymentSecure checkout · stripe