Run Your Own AI (Mixtral) on Your Machine
Discover how hosting Mixtral, an open-source large language model, on a cloud instance can help you own your AI.
Have you ever wondered how to maximize your control over an AI system while ensuring scalability and customization? Running Mixtral LLM on your own cloud instance not only gives you unparalleled flexibility but also enhances your data security. This post explores how to deploy Mixtral Instruct using llama.cpp on a cloud instance, enabling you to own your AI.
Join the AI BootCamp!
Ready to dive into the world of AI and Machine Learning? Join the AI BootCamp to transform your career with the latest skills and hands-on project experience. Learn about LLMs, ML best practices, and much more!
Mixtral Instruct v0.1
Mixtral1 represents a significant leap in the open-source AI landscape, boasting top-tier performance as a sparse mixture of experts model (MoE) that excels in both speed and accuracy. Licensed under the permissive Apache 2.0, it offers an impressive balance of cost and performance, matching or surpassing benchmarks set by models like GPT-3.5.
- Handles 32k tokens
- Multilingual support (English, German, French, Italian, Spanish)
- Finetuned into a instruction following model
- About 45B parameters (not 56B as you might expect from the name)
Cloud Instance Setup
To run Mixtral on a cloud instance, you need to set up a virtual machine (VM). In this tutorial, we’ll use a Runpod2 instance with a GPU. Of course, any other cloud provider like AWS, GCP, or Azure would work as well.
Here are the steps to set up a cloud instance:
- Sign up for a Runpod account
- Go to https://www.runpod.io/console/deploy and create a new instance with a GPU (I’ll use A6000 with 48GB VRAM)
- Select
Pytorch 2.2.0as the Pod template and configure it as follows:
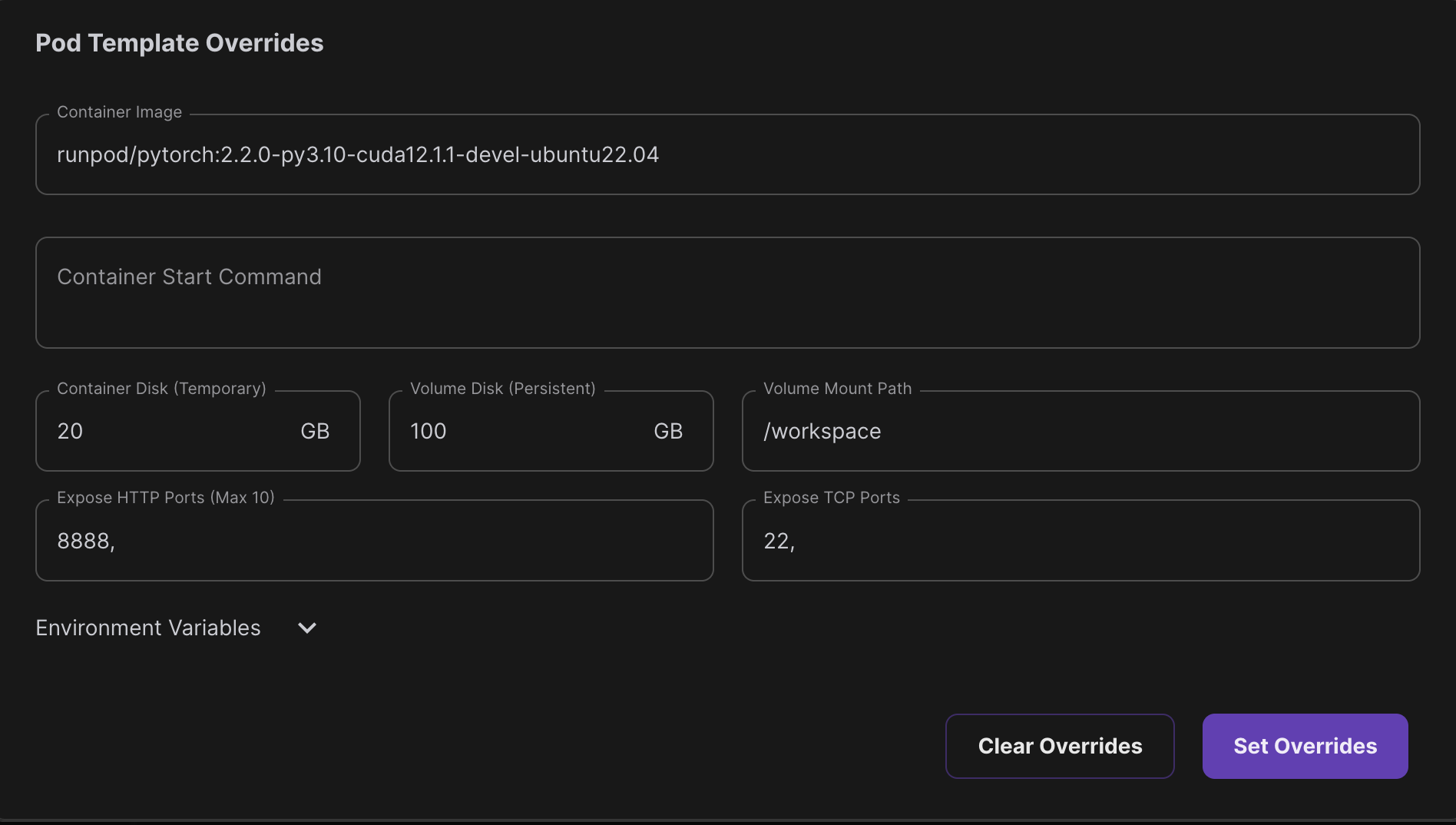
- Enable
SSH Terminal AccessandStart Jupyter Notebook - Click
Deployand wait for the instance to be ready
Install llama.cpp
Running Mixtral would require about 90GB of VRAM in half precision (FP16) - 2 bytes for each parameter (45B parameters). Luckily, the llama.cpp library can help you run Mixtral on a GPU with 48GB of VRAM.
Llama.cpp3 is a highly optimized library designed to facilitate large language model (LLM) inference across diverse platforms, that is fast (tokens/second) inference and low resource usage. Most people use it to run LLMs on CPUs, but it also works wonders on GPUs.
Let’s start by installing the Python bindings for llama.cpp. You can install
llama-cpp-python from PyPI. In the terminal of your cloud instance, run the
following commands:
export LLAMA_CUBLAS=1
CMAKE_ARGS="-DLLAMA_CUBLAS=on" FORCE_CMAKE=1 pip install llama-cpp-python==0.2.61
pip install huggingface_hub==0.22.2Then connect to the Jupyter Lab from the machine options and create a new notebook.
Load the Model
To run Mixtral with llama.cpp we need a model in GGUF format. You can download the Mixtral Instruct v0.14 model from the Hugging Face Hub. Here’s how you can do it:
import os
from huggingface_hub import hf_hub_download
HF_REPO_NAME = "TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF"
HF_MODEL_NAME = "mixtral-8x7b-instruct-v0.1.Q8_0.gguf"
LOCAL_DIR_NAME = "models"
os.makedirs(LOCAL_DIR_NAME, exist_ok=True)
model_path = hf_hub_download(
repo_id=HF_REPO_NAME, filename=HF_MODEL_NAME, cache_dir=LOCAL_DIR_NAME
)
model_pathThe model is almost 50GB, so it might take a while to download. Once you have the model, you can load it using llama.cpp:
from llama_cpp import Llama
llm = Llama(
model_path=model_path,
n_ctx=2048, # max tokens -> increase to fit more input/output
n_threads=16, # number of CPU cores
n_gpu_layers=35 # offload every layer on the GPU
)The loading of the model takes a while but once it’s done, you should see this as the final output:
Guessed chat format: mistral-instruct
The library correctly guessed the chat format as mistral-instruct. Now you can
prompt the model:
llm.create_chat_completion(
messages = [
{
"role": "user",
"content": "You are a world-renowned paper salesman. Write a single sentence that sells your paper to an AI entity"
}
]
)Our high-quality, durable paper is perfect for your data processing needs, offering exceptional performance and longevity, ensuring accurate and reliable results for all your AI applications.
Interesting response! Let’s have a look at the full output:
{
"id": "chatcmpl-a4cb3d89-df24-4ab1-8e27-83cab52679ea",
"object": "chat.completion",
"created": 1713113933,
"model": "models/models--TheBloke--Mixtral-8x7B-Instruct-v0.1-GGUF/snapshots/fa1d3835c5d45a3a74c0b68805fcdc133dba2b6a/mixtral-8x7b-instruct-v0.1.Q8_0.gguf",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": " Our high-quality, durable paper is perfect for your data processing needs, offering exceptional performance and longevity, ensuring accurate and reliable results for all your AI applications."
},
"logprobs": "None",
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 33,
"completion_tokens": 35,
"total_tokens": 68
}
}We get roughtly 37 tokens per second on a A6000 GPU. This is a great result considering the model size and the fact that we are running it on a quite old GPU.
Conclusion
Running Mixtral on a cloud instance is a great way to own your AI. It gives you the flexibility to customize the model and the infrastructure to suit your needs. Now it’s your turn to explore the possibilities!
Join the The State of AI Newsletter
Every week, receive a curated collection of cutting-edge AI developments, practical tutorials, and analysis, empowering you to stay ahead in the rapidly evolving field of AI.
I won't send you any spam, ever!