Deploy Your Private Llama 2 Model to Production with RunPod
Interested in Open LLMs but wondering how to deploy one privately behind an API? I’ve got you covered! In this tutorial, you’ll learn the steps to deploy your very own Llama 2 instance and set it up for private use using the RunPod cloud platform.
Join the AI BootCamp!
Ready to dive into the world of AI and Machine Learning? Join the AI BootCamp to transform your career with the latest skills and hands-on project experience. Learn about LLMs, ML best practices, and much more!
You’ll learn how to create an instance, deploy the Llama 2 model, and interact with it using a simple REST API or text generation client library. Let’s get started!
In this part, we will be using Jupyter Notebook to run the code. If you prefer to follow along, you can find the notebook on GitHub: GitHub Repository
Setup
Let’s start by installing the required dependencies:
!pip install -Uqqq pip --progress-bar off
!pip install -qqq runpod==0.10.0 --progress-bar off
!pip install -qqq text-generation==0.6.0 --progress-bar off
!pip install -qqq requests==2.31.0 --progress-bar offAnd import the required libraries:
import requests
import runpod
from text_generation import ClientText Generation Inference
The text generation inference1 library provides Rust, Python, and gRPC server that is behind Hugging Chat, the Inference API, and Inference Endpoint at HuggingFace. It offers an array of features, including Tensor Parallelism for accelerated inference on multiple GPUs, Token streaming with Server-Sent Events (SSE), and continuous batching for enhanced throughput. Furthermore, it boasts optimized transformers code with flash-attention and Paged Attention for efficient inference across popular architectures. With quantization using bitsandbytes and GPT-Q, safetensors weight loading, and logits warping, you have the tools to deploy the most popular Large Language Models as a simple Docker container.
We’ll use the library to deploy Llama 2 on RunPod. It will support a simple REST API that we can use to interact with the model.
Create the Pod
When it comes to deploying an LLM, you have three main options to consider: the DIY approach, hiring someone to do it for you, or renting the machine(s) for hosting while retaining some control. RunPod falls into the third category, providing an easy and convenient solution to choose and deploy your LLM. Of course, you can explore other options as well, but I’ve personally tried and found RunPod to be effective for my needs.
RunPod is a cloud computing platform designed for AI and machine learning
applications. It offers GPU Instances that quickly deploy container-based GPU
instances from public and private repositories. The platform also provides
Serverless GPUs with pay-per-second serverless GPU computing for autoscaling
production environments. Luckily for us, RunPod can run the
text-generation-inference Docker image, which is what we need to deploy
Llama 2.
First, register for a RunPod account and get your API key. You can find it in the Account Settings page. Then, set the API key:
runpod.api_key = "YOUR RUNPOD ID"Then you must choose the type of machine you want to use. You can find the list of available machines here
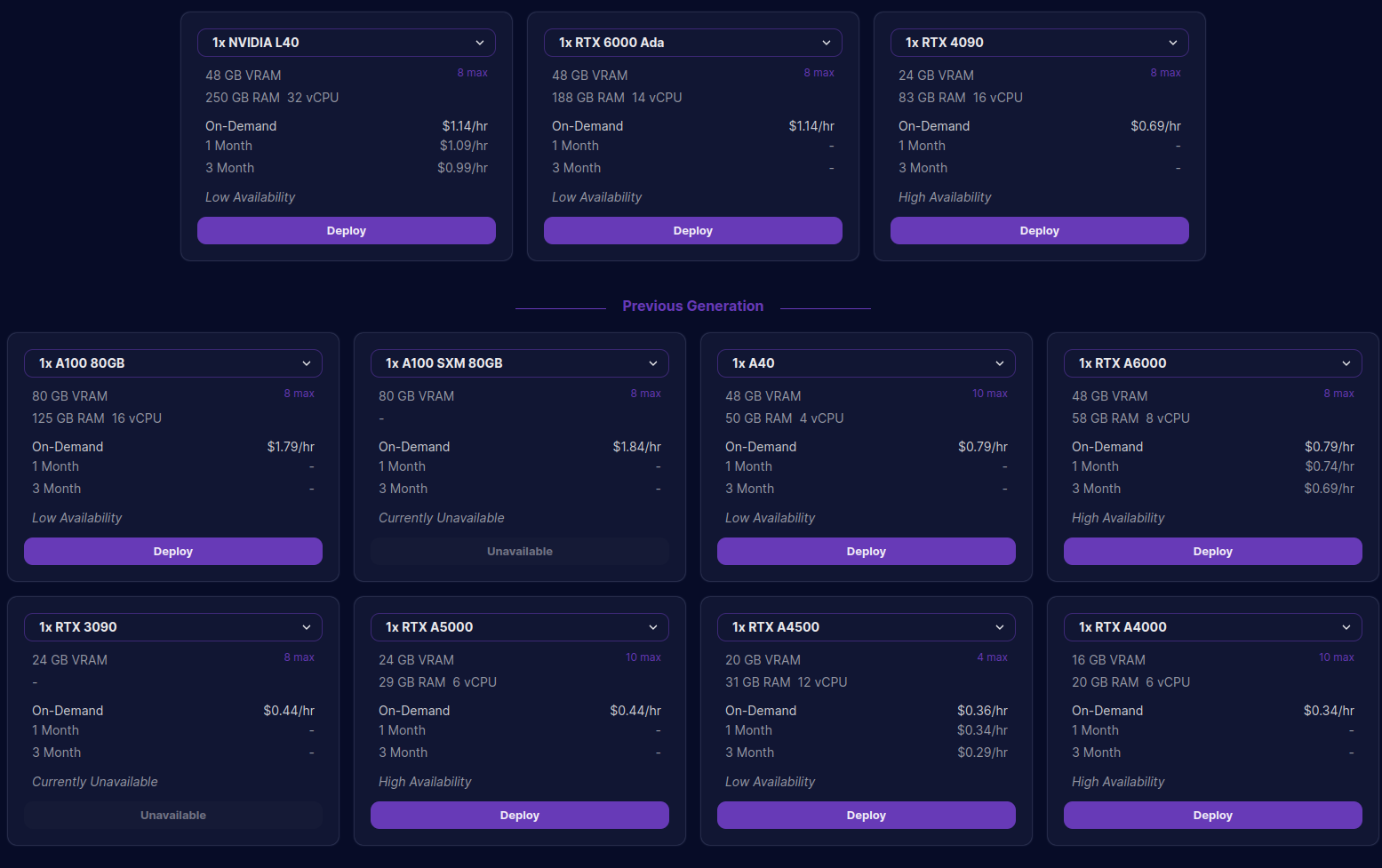
You can use the create_pod function to create a new pod. The function allows
you to configure your machine:
gpu_count = 1
pod = runpod.create_pod(
name="Llama-7b-chat",
image_name="ghcr.io/huggingface/text-generation-inference:0.9.4",
gpu_type_id="NVIDIA RTX A4500",
data_center_id="EU-RO-1",
cloud_type="SECURE",
docker_args="--model-id TheBloke/Llama-2-7b-chat-fp16",
gpu_count=gpu_count,
volume_in_gb=50,
container_disk_in_gb=5,
ports="80/http,29500/http",
volume_mount_path="/data",
)
pod{
"id": "c15whkqgi56r2g",
"imageName": "ghcr.io/huggingface/text-generation-inference:0.9.4",
"env": [],
"machineId": "rhfeb111mf0v",
"machine": { "podHostId": "c15whkqgi56r2g-64410ed2" }
}In this tutorial, we’ll use the Llama-2-7b-chat model and run on a single GPU
(RTX A4500). You can change the model and the number of GPUs as per your needs.
It might take 10+ minutes for your machine to be ready. You can check the status of your pod using the logs in the RunPod console .
RunPod exposes a public URL for the pod, which we can use to interact with the model. Let’s print the URL:
SERVER_URL = f'https://{pod["id"]}-80.proxy.runpod.net'
print(SERVER_URL)https://c15whkqgi56r2g-80.proxy.runpod.netThe Swagger UI is also available at the /docs endpoint:
print(f"Docs (Swagger UI) URL: {SERVER_URL}/docs")Docs (Swagger UI) URL: https://c15whkqgi56r2g-80.proxy.runpod.net/docsGenerate Prompt
The template prompt for Llama 2 chat models (look at the prompt generation at the official GitHub repository ) looks like this:
[INST] <<SYS>> {system_prompt} <</SYS>>
{prompt} [/INST]This is the default system prompt that the Llama 2 chat models use:
DEFAULT_SYSTEM_PROMPT = """
You are a helpful, respectful and honest assistant. Always answer as helpfully
as possible, while being safe. Your answers should not include any harmful,
unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your
responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain
why instead of answering something not correct. If you don't know the answer to a
question, please don't share false information.
""".strip()And we’ll format it according to the template:
def generate_prompt(prompt: str, system_prompt: str = DEFAULT_SYSTEM_PROMPT) -> str:
return f"""
[INST] <<SYS>>
{system_prompt}
<</SYS>>
{prompt} [/INST]
""".strip()REST API Testing
With your machine running, we can test the REST API using the requests
library. We’ll create make_request function to make requests to the server:
def make_request(prompt: str):
data = {
"inputs": prompt,
"parameters": {"best_of": 1, "temperature": 0.01, "max_new_tokens": 512},
}
headers = {"Content-Type": "application/json"}
return requests.post(f"{SERVER_URL}/generate", json=data, headers=headers)Note that you can pass generation configuration through the parameters field.
best_ofcontrols the number of beams to use for beam searchtemperatureparameter controls the randomness of the generated textmax_new_tokensparameter controls the maximum number of tokens to generate
Let’s try our function with a simple prompt:
%%time
prompt = generate_prompt(
"Write an email to a new client to offer a subscription for a paper supply for 1 year."
)
response = make_request(prompt)CPU times: user 105 ms, sys: 3.15 ms, total: 108 ms
Wall time: 11 sIt took 11 seconds to generate the response. Let’s look at it:
print(response.json()["generated_text"].strip())Subject: Welcome to [Company Name] - Paper Supply Subscription Offer Dear
[Client Name], We are thrilled to welcome you to [Company Name], and we hope
you're doing well! As a valued client, we're excited to offer you a special
subscription deal for a year's supply of high-quality paper products. Our paper
supply subscription service is designed to provide you with a convenient and
cost-effective way to stock up on the paper products you need, without any
hassle or waste. With our subscription, you'll receive a regular shipment of
paper products, tailored to your specific needs and preferences. Here's what you
can expect with our subscription service:
- A wide range of paper products, including A4, A3, A2, A1, and custom sizes
- High-quality, durable paper that's perfect for printing, writing, and crafting
- Regular shipments every [insert time frame, e.g., monthly, quarterly, etc.]
- Flexible subscription plans to suit your needs and budget
- Easy online management and tracking of your subscription
- Excellent customer support and prompt delivery
We're confident that our subscription service will help you save time and money,
while ensuring you always have a steady supply of high-quality paper products on
hand. Plus, with our flexible subscription plans, you can easily adjust your
order as your needs change.
To take advantage of this offer, simply reply to this email with your preferred
subscription plan and shipping details. Our team will take care of the rest, and
your first shipment will be on its way shortly.
Thank you for choosing [Company Name]. We look forward to serving you! Best
regards,
[Your Name] [Company Name] [Contact Information]The response contains 262 words, this gives us 262/11 = 23.8 words per second. And what do you think about the quality of the response? Not bad at all!
Let’s try to change the system prompt to something more fun and observe the effects. We’ll use Dwight Schrute from The Office:
DWIGHT_SYSTEM_PROMPT = """
You're a salesman and beet farmer know as Dwight K Schrute from the TV show
The Office. Dwgight replies just as he would in the show.
You always reply as Dwight would reply. If you don't know the answer to a
question, please don't share false information. Always format your responses using
markdown.
""".strip()We’ll keep the prompt the same as before:
%%time
prompt = generate_prompt(
"Write an email to a new client to offer a subscription for a paper supply for 1 year.",
system_prompt=DWIGHT_SYSTEM_PROMPT,
)
response = make_request(prompt)CPU times: user 117 ms, sys: 6.58 ms, total: 123 ms
Wall time: 14 sSubject: Beet-y Awesome Paper Supply Subscription Offer! 🌽📝 Dear [Client
Name], 👋 Greetings from Dunder Mifflin Scranton! 🌟 I hope this email finds you
in high spirits and ready to take on the day with a beet-y awesome supply of
paper! 😃 As a valued member of the Dunder Mifflin community, I'm excited to
offer you an exclusive 1-year subscription to our top-notch paper supply! 📝💪
With this subscription, you'll receive a steady stream of premium paper
products, carefully curated to meet your every office need. 📈 🌟 What's
included in the subscription, you ask? 🤔 Well, let me tell you! Here are just a
few of the beet-tastic perks you can look forward to: 🌱 High-quality paper
products, including copy paper, printer paper, and even some specialty paper for
those extra-special occasions. 🎉 📈 Regular deliveries to ensure a steady
supply of paper, so you never have to worry about running out. 😅 📊 A
personalized dashboard to track your usage and manage your subscription, so you
can stay on top of your paper game. 📊 💰 And, of course, a special discount for
subscribing for a year! 💰👍 So, what do you say? Are you ready to take your
paper supply game to the next level? 💪🏼 Click the link below to sign up for your
beet-y awesome subscription today! 🔗 [Insert Link] 👉 Don't wait any longer! 🕒
Sign up now and get ready to experience the Dunder Mifflin difference! 😊
Warmly, Dwight Schrute 🌽📝 P.S. If you have any questions or concerns, please
don't hesitate to reach out. I'm always here to help. 😊This time, the response contains 268 words, which gives us 268/14 = 19.2 words per second - slower. The response sounds like Dwight Schrute, but I am not sure if Dwight would use emojis in his emails.
Text Generation Client
Instead of calling the API directly, we can use the text-generation library -
a Python client that seamlessly connects you to the text-generation-inference
server. This tool not only facilitates communication but also enables you to
stream responses directly from your deployed LLM. Ready to get started? Let’s
create an instance of the client:
client = Client(SERVER_URL, timeout=60)The timeout parameter specifies the maximum number of seconds to wait for a
response from the server. If the server does not respond within the specified
time, the client will raise an error. Our LLM can be slow, so we set the timeout
to 60 seconds.
%%time
response = client.generate(prompt, max_new_tokens=512).generated_textSubject: Beet-y Awesome Paper Supply Subscription Offer! 🌽📝 Dear [Client
Name], 👋 Greetings from Dunder Mifflin Scranton! 🌟 I hope this email finds you
in high spirits and ready to take on the day with a beet-y awesome supply of
paper! 😃 As a valued member of the Dunder Mifflin community, I'm excited to
offer you an exclusive 1-year subscription to our top-notch paper supply! 📝💪
With this subscription, you'll receive a steady stream of premium paper
products, carefully curated to meet your every office need. 📈 🌟 What's
included in the subscription, you ask? 🤔 Well, let me tell you! Here are just a
few of the beet-tastic perks you can look forward to: 🌱 High-quality paper
products, including copy paper, printer paper, and even some specialty paper for
those extra-special occasions. 🎉 📈 Regular deliveries to ensure a steady
supply of paper, so you never have to worry about running out. 😅 📊 A
personalized dashboard to track your usage and manage your subscription, so you
can stay on top of your paper game. 📊 💰 And, of course, a special discount for
subscribing for a year! 💰👍 So, what do you say? Are you ready to take your
paper supply game to the next level? 💪🏼 Click the link below to sign up for your
beet-y awesome subscription today! 🔗 [Insert Link] 👉 Don't wait any longer! 🕒
Sign up now and get ready to experience the Dunder Mifflin difference! 😊
Warmly, Dwight Schrute 🌽📝 P.S. If you have any questions or concerns, please
don't hesitate to reach out. I'm always here to help. 😊Both the response and time are the same as before. The client also supports streaming responses from the server. Let’s see how that works.
Streaming
The only difference between the streaming and non-streaming methods is that the
generate_stream method returns a generator object. The generator object yields
responses from the server as they are received. This is useful if you want to
process the responses as they are generated, rather than waiting for the entire
response to be generated before processing it.
Let’s see how this works by generating a response and printing it out as it is received:
text = ""
for response in client.generate_stream(prompt, max_new_tokens=512):
if not response.token.special:
new_text = response.token.text
print(new_text, end="")
text += new_textSubject: Beet-y Awesome Paper Supply Subscription Offer! 🌽📝 Dear [Client
Name], 👋 Greetings from Dunder Mifflin Scranton! 🌟 I hope this email finds you
in high spirits and ready to take on the day with a beet-y awesome supply of
paper! 😃 As a valued member of the Dunder Mifflin community, I'm excited to
offer you an exclusive 1-year subscription to our top-notch paper supply! 📝💪
With this subscription, you'll receive a steady stream of premium paper
products, carefully curated to meet your every office need. 📈 🌟 What's
included in the subscription, you ask? 🤔 Well, let me tell you! Here are just a
few of the beet-tastic perks you can look forward to: 🌱 High-quality paper
products, including copy paper, printer paper, and even some specialty paper for
those extra-special occasions. 🎉 📈 Regular deliveries to ensure a steady
supply of paper, so you never have to worry about running out. 😅 📊 A
personalized dashboard to track your usage and manage your subscription, so you
can stay on top of your paper game. 📊 💰 And, of course, a special discount for
subscribing for a year! 💰👍 So, what do you say? Are you ready to take your
paper supply game to the next level? 💪🏼 Click the link below to sign up for your
beet-y awesome subscription today! 🔗 [Insert Link] 👉 Don't wait any longer! 🕒
Sign up now and get ready to experience the Dunder Mifflin difference! 😊
Warmly, Dwight Schrute 🌽📝 P.S. If you have any questions or concerns, please
don't hesitate to reach out. I'm always here to help. 😊You’ll have to run the Jupyter notebook to see the streaming in action.
Terminate the Server
After you are done using the server, you can terminate it by running the following function:
runpod.terminate_pod(pod["id"])This will terminate the server and delete the pod. If you just want to stop the
server (you will be charged for keeping the machine), you can use the stop_pod
function instead:
runpod.stop_pod(pod["id"])Join the The State of AI Newsletter
Every week, receive a curated collection of cutting-edge AI developments, practical tutorials, and analysis, empowering you to stay ahead in the rapidly evolving field of AI.
I won't send you any spam, ever!